
Vad är Dataverse?
Microsoft Dataverse är en molnbaserad, hanterad datatjänst byggd på Azure som organiserar affärsdata och lågkodlogik på ett strukturerat, säkert och regelefterlevande sätt. Den finns i Microsofts moln – inte på egna servrar – och nås via internet utan lokal installation. Microsoft driver och underhåller Dataverse i molnet, med regionala driftsättningsalternativ för att stödja krav på datalagring och regelefterlevnad.
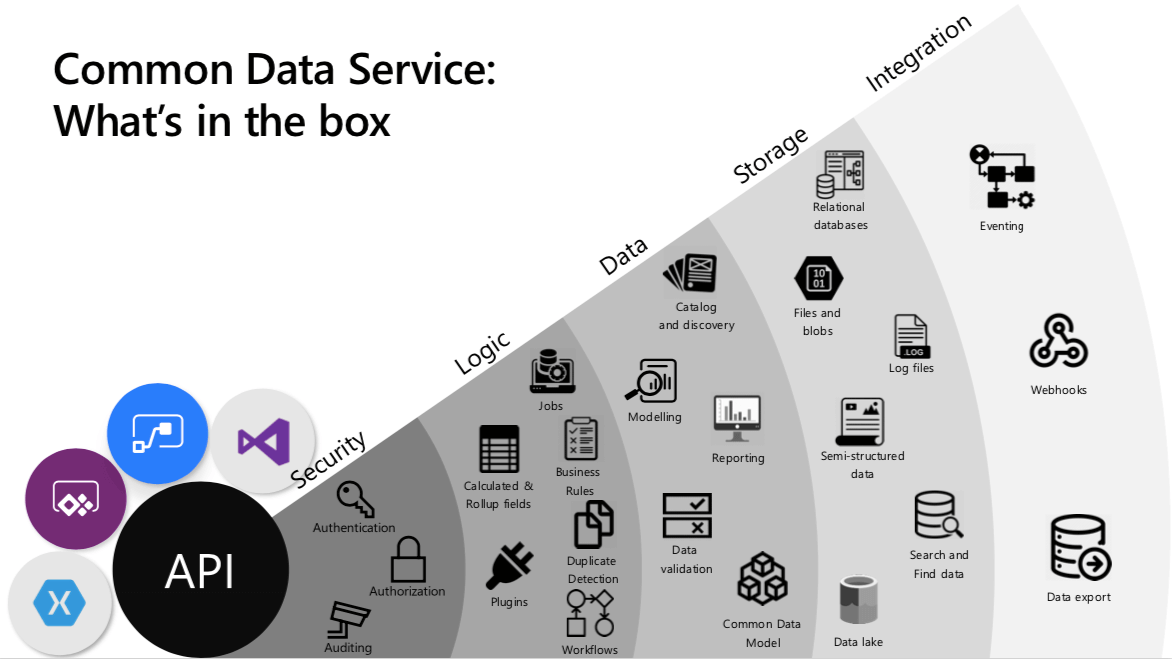
I hjärtat av Dataverse finns begreppet miljö. En miljö är en enskild Dataverse-instans som innehåller tabeller, relationer och affärslogik, tillsammans med stödresurser som filer och bilder.
Inom en miljö lagras data i tabeller. Varje tabell består av rader och kolumner. En rad representerar en enskild post, och varje kolumn innehåller en specifik typ av värde – till exempel en persons namn, en ålder, ett datum eller ett belopp. Dataverse inkluderar en rik uppsättning standardtabeller som täcker vanliga affärsscenarier, och du kan definiera relationer mellan dem.
Du kan ha en eller flera Dataverse-miljöer – till exempel separata miljöer för pilot och produktion. Varje miljö börjar med en gemensam basuppsättning av Dataverse-tabeller och säkerhetsfunktioner. Din modell utökas sedan när du lägger till lösningar (och eventuellt Dynamics 365-appar), plus egna tabeller och den affärslogik din verksamhet behöver.
Den här konsekvensen innebär att lösningar byggda på standardtabeller i Dataverse kan delas mellan team, regioner eller till och med andra organisationer som också använder Dataverse – utan att behöva bygga om den underliggande datastrukturen varje gång.
När din data väl finns i Dataverse kan den nås och uppdateras på flera sätt. Du kan arbeta direkt via Power Apps, Power Automate och andra Power Platform-verktyg, eller ansluta till Dataverse från externa applikationer via kopplingsprogram och API:er.
Dataverse är det styrda dataskiktet bakom Power Platform och många Dynamics 365-applikationer. Det innebär att du kan börja med ett enskilt operativt användningsfall och expandera utan att behöva bygga om din datamodell varje gång.
Tabeller i Dataverse
En Dataverse-tabell definierar den information du vill spåra i form av rader och kolumner. Varje rad representerar en enskild affärsinstans – till exempel en kund, en faktura eller ett serviceärende. Varje kolumn representerar ett specifikt attribut som företagsnamn, telefonnummer, belopp, status eller förfallodatum.
En Dataverse-tabell gör tre praktiska saker: den lagrar posterna, standardiserar fälten så att rapporteringen förblir konsekvent, och tillämpar regler och säkerhet så att team inte kan kringgå policyn.
För ledningen handlar valet av tabelltyp om styrning och kostnad. Använd standard- eller anpassade tabeller för grundläggande operativa poster, virtuella tabeller när ett annat system måste förbli sanningskälla, och elastiska tabeller bara när volymen kräver det och du kan acceptera avvägningarna.
| Tabelltyp | Använd för | Var den lagras | Noteringar |
|---|---|---|---|
| Standard / Anpassad | Grundläggande affärsentiteter (Konto, Kontakt, anpassade entiteter) | Dataverse | Operativa tabeller som fungerar som sanningskälla |
| Aktivitet | Tidsbaserade interaktioner (e-post, samtal, uppgift m.m.) | Dataverse | Utformad för att spåra e-post och samtal och koppla dem till en kund eller ett ärende |
| Virtuell | Visa extern data utan att kopiera den | Extern källa | Ofta skrivskyddad; styrningsfunktioner kan vara begränsade |
| Elastisk | Mycket hög volym eller tidsserieliknande data | Dataverse (skalbar lagring) | Optimerad för skala; vissa relationsbeteenden skiljer sig åt |
Tabellägande är ett styrningsbeslut eftersom det avgör vem som kan komma åt poster och hur ansvarighet fungerar. Välj användar- eller teamägda tabeller för arbete som har en ansvarig ägare, och välj organisationsägda tabeller för delad referensdata där åtkomst är konsekvent i hela verksamheten.
Elastiska tabeller är utformade för mycket hög datavolym, men de gör avkall på vissa styrnings- och relationsfunktioner – de passar därför bäst för händelsebaserad data snarare än grundläggande affärsposter. Se Bilaga A.1 för begränsningar med elastiska tabeller.
Standard- och anpassade tabeller i Dataverse-databasen innehåller vanligtvis strukturerad operativ data för din verksamhet. Aktivitetstabeller är idealiska när du behöver en kronologisk historik av interaktioner kring en post. Virtuella och elastiska tabeller används i mer specialiserade scenarier – antingen när du behåller data i externa system eller arbetar med mycket stora datamängder.
Kolumner i Dataverse
Kolumner är där datakvalitet och regelefterlevnad blir verkställbara. Att välja rätt fälttyper minskar rensningsarbete i rapportering, och säkerhet på kolumnnivå gör att känsliga attribut bara är synliga för rätt roller.
Varje tabell består av en uppsättning kolumner, och varje kolumn har ett namn, en datatyp och valfria beteenden som Dataverse tillämpar. Varje tabell inkluderar en primärnyckel (unikt ID) och en primärkolumn (den läsvänliga etikett som visas i listor och sökningar).
Dataverse tillhandahåller också systemkolumner såsom skapade/ändrade datum, skapad av/ändrad av, ägare och status för att stödja granskning, säkerhet och livscykelspårning.
Utöver det definierar du affärskolumner som matchar dina verkliga attribut. När du lägger till en kolumn väljer du en datatyp, till exempel:
- Text eller flerradig text för namn och beskrivningar
- Tal, decimal eller valuta för kvantiteter och finansiella värden
- Datum och tid för förfallodatum och tidsstämplar
- Val eller Ja/Nej för kontrollerade listor och flaggor
- Uppslagning för att koppla en post till en annan tabell – till exempel koppla en order till en kund
- Fil eller bild för att bifoga stöddokument eller bilder till en post
I praktiken bör ledare se till att Dataverse stödjer strukturerade fält (text, siffror, datum), kontrollerade val och säkra kopplingar mellan poster – så att rapporteringen förblir konsekvent och känsliga fält förblir skyddade.
Dataverse lagrar dessa värden på ett typsäkert sätt i den underliggande databasen och fillagringen. Det innebär att systemet kan validera indata, indexera och söka i data effektivt, och säkerställa att ogiltiga värden inte kan matas in i ett fält.
Kolumner kan också bära logik. Beräknade kolumner härleder sitt värde från andra kolumner i samma rad – till exempel ett fullständigt namn eller en marginalkalkyl. Eftersom dessa definieras på kolumnen och körs av Dataverse tillämpas samma logik konsekvent i alla appar och processer som använder tabellen.
Slutligen deltar kolumner i säkerhet och styrning. För känsliga fält kan du aktivera säkerhet på kolumnnivå så att bara specifika roller kan visa eller redigera attributet – även om de kan se resten av posten. Du kan också aktivera granskning på valda kolumner för att spåra ändringar av kritisk data över tid.
Relationer och affärslogik i Dataverse
Tabellrelationer i Dataverse
Hur fungerar relationer i Dataverse?
Relationer är hur Dataverse bygger en sammanhängande bild av verksamheten – till exempel genom att koppla kunder till order och ärenden. Affärsnyttan är bättre rapportering, tydligare ansvarighet och färre avstämningscykler mellan team.
I Dataverse definierar relationer hur rader i en tabell är kopplade till rader i en annan tabell – eller till och med rader i samma tabell. I den dagliga datamodelleringen implementeras detta via en uppslagskolumn.
Att lägga till en uppslagskolumn skapar en 1:N-relation och gör det möjligt för utvecklare att placera uppslagningen i formulär så att användare kan koppla en underordnad post till en överordnad post vid datainmatning. Relationer är avsedda för formella, återkommande kopplingar som är viktiga för navigering, rapportering och konsekvent appbeteende.
För mindre formella, ad hoc-kopplingar som du inte behöver modellera konsekvent stödjer Dataverse också anslutningar som ett lättare alternativ.
Typer av tabellrelationer
I utvecklarupplevelsen kan du se 1:N (En-till-många), N:1 (Många-till-en) och N:N (Många-till-många), men Dataverse har två tabellrelationstyper i datamodellen: en-till-många och många-till-många. "N:1" visas i gränssnittet eftersom det är den relaterade tabellens vy av en 1:N-relation.
- En-till-många-relationer: en överordnad rad kan kopplas till många underordnade rader, möjliggjort via en uppslagskolumn i den underordnade tabellen.
- Många-till-många-relationer: många rader i en tabell kan kopplas till många rader i en annan; Dataverse använder en korsningstabell i bakgrunden.
En praktisk modelleringsregel är att som standard använda 1:N när du tydligt kan förklara ägarskap och rapportering ("dessa poster tillhör den föräldern"), och reservera N:N för verkliga medlemskapsrelationer där båda sidor behöver flera kopplingar. För implementering av många-till-många-relationer, se Bilaga A.2.
OBS Dataverse har ingen inbyggd 1:1-relationstyp. En-till-en-scenarier implementeras vanligtvis som 1:N med en unik begränsning för att säkerställa kardinalitet.
Beteende för tabellrelationer
Relationsbeteende definierar vad Dataverse ska göra med relaterade "underordnade" poster när något förändras i en "överordnad" post i en 1:N-relation.
Slutsats för ledningen: Relationsbeteende avgör om ditt system bevarar bevis, förhindrar oavsiktlig radering och håller ägarskapsändringar hanterbara i skala. Om din organisation håller på att gå från kalkylblad till styrd drift är dessa inställningar en av anledningarna till att Dataverse beter sig som ett riktigt affärssystem snarare än en samling länkade listor.
| Beteendetyp | Vad det innebär | Vad som händer vid radering av förälder |
|---|---|---|
| Referentiell, Ta bort länk | Föräldraändringar påverkar inte barnet; relationer kan tas bort utan att poster raderas | Underordnade poster finns kvar; länken tas bort |
| Referentiell, Begränsa radering | Förhindrar radering av en förälder om beroende underordnade poster finns | Föräldern kan inte raderas förrän barnen tagits bort |
| Överordnad | Underordnade poster behandlas som beroende av föräldern | Underordnade poster raderas tillsammans med föräldern |
| Anpassad | Du väljer utfall per åtgärd | Blandat, baserat på din policy |
I praktiken handlar det om tre beslut: vad som händer vid radering, vad som händer när ägarskap ändras, och om åtkomst ska ärvas till relaterade poster. Du behöver inte konfigurera varje åtgärd på ett komplext sätt, men du bör uttryckligen bestämma din "standardhållning" – särskilt för radering och åtkomstarvning.
Praktiska skyddsräcken som är viktiga för ledningen:
- Standardinställning: säkerhet vid radering. Kaskadradering bör reserveras för genuint beroende operativa detaljer. För allt med revisions- eller avtalsvärde är blockering av radering (Begränsa radering) ofta en säkrare hållning.
- Använd kaskadtilldelning för att minska operativt arbete. När ägarskap ändras (teamomflyttningar, territoriella förändringar) kan kaskadtilldelning minska manuell städning – särskilt om du begränsar det till aktiva arbetsuppgifter snarare än historiska poster.
- Behandla kaskaddelning som ett styrningsbeslut. När åtkomst till en förälder automatiskt ger åtkomst till barn skalas behörigheter effektivt, men det ökar också behovet av disciplin i rolldesign och löpande åtkomstkontroller.
Relationsbeteende är en av mekanismerna som gör Dataverse tillförlitligt i skala. Det omvandlar "postlänkar" till verkställbara regler om radering, ägarskap och åtkomst. När det är medvetet konfigurerat minskar det undvikbar risk (oavsiktlig radering, föräldralösa poster, alltför bred åtkomst) samtidigt som driften förblir effektiv när team och processer växer.
Affärslogik i Dataverse
Vad är affärslogik?
För ledare är affärslogik hur policy blir konsekvent utförande. Det minskar omarbete eftersom team inte kan "arbeta runt" processen i olika appar, och det förbättrar revisionsberedskapen eftersom samma regler gäller oavsett hur data matas in.
Relationer beskriver struktur: hur poster kopplas samman. Affärslogik beskriver beteende: vad som måste stämma när data skapas eller ändras, och vad som bör hända härnäst i en process.
I Dataverse är målet att hålla det beteendet konsekvent även när samma tabell används av olika ingångspunkter – till exempel canvas-appar, modellstyrda appar, flöden och API:er.
Affärsregler: lågkodsverktyg för logik
Affärsregler är det primära lågkodsverktyget för att tillämpa logik och valideringar utan att skriva kod eller skapa anpassade kodtillägg (när det krävs). När de definieras för en tabell kan de tillämpas på alla formulär och på servernivå, och de gäller för både canvas-appar och modellstyrda appar om tabellen används i appen.
Detta gör dem väl lämpade för krav på "datakorrekthet" – till exempel obligatoriska fält, villkorsstyrd validering eller standardvärden.
En begränsning är att inte alla affärsregelåtgärder är tillgängliga för canvas-appar. Affärsregler är en bra bas, men du bör fortfarande validera det slutliga beteendet i de specifika apptyper du planerar att driftsätta.
Processlogik och automatisering av utfall
När behovet inte bara är validering utan även processutförande erbjuder Dataverse två vanliga mönster.
Affärsprocessflöden vägleder användare genom de steg organisationen definierar, och ger en strukturerad upplevelse som driver arbetet mot ett avslut – och kan anpassas efter säkerhetsroll. Detta passar bäst när du vill ha konsekventa steg och datainsamling inuti användarupplevelsen.
För händelsedriven automatisering och orkestration över flera system används vanligtvis Power Automate-flöden tillsammans med Dataverse. På det här skiktet är "affärslogiken" den sekvens av åtgärder som körs när en post ändras – till exempel routing, notifieringar, eskalering, synkronisering eller godkännanden.
Rekommendation: Börja med affärsregler för korrekthet, lägg till affärsprocessflöden eller Power Automate för processrörelse, och använd plug-ins bara när du måste tillämpa komplex logik centralt och tillförlitligt. Det håller lösningen underhållbar och ger dig ändå en väg att hantera avancerade krav.
Datatyper och lagringsöverväganden i Dataverse
När folk pratar om "datatyper i Dataverse" menar de ofta två olika saker. Det första är kolumndatatyper (de fälttyper du väljer när du modellerar en tabell). Det andra är datakategorier (den typ av affärsdata som Dataverse passar bäst för att lagra och styra).
Dataverse inkluderar en bred uppsättning kolumntyper som du ofta använder i appar för små och medelstora företag: text, siffror, datum, val, uppslagningar och rikare typer som filer och bilder. De styr validering, sökbeteende, relationell integritet och vad Power Apps och Power Automate kan göra med din data utan anpassad kod.
Dataverse kan lagra bilder och filer i dedikerade kolumntyper. Bilder är optimerade för vanliga appscenarier och har egna begränsningar. Dataverse stödjer också filkolumner, men det fungerar bäst för dokument kopplade till en specifik post snarare än som ett fullständigt dokumentbibliotek. Kapacitet mäts som databas, fil och logg – se Lagring och licensiering för detaljer.
Typer av data som Dataverse hanterar väl
Dataverse är starkast när det fungerar som ett operativt sanningssystem för affärsprocesser. Bäst lämpat är data som behöver struktur, relationer och konsekvent beteende över appar, flöden och integrationer.
| Datakategori som Dataverse hanterar väl | Exempel | Varför det passar Dataverse |
|---|---|---|
| Operativa affärsposter | Kunder, ärenden, arbetsorder, fakturor | Enkelt att organisera, koppla samman och kontrollera med rollbaserade behörigheter |
| Referens- och kontrollerade värden | Status, kategori, region, tjänstetyp | Håller val konsekventa och minskar rörig data |
| Processkontextdata | Status, fas, ägare, förfallodatum, SLA KPI-fält | Håller arbetsflödestillstånd och routingdata säkrad, granskad och konsekvent |
| Relationslänkdata | Uppslagningar (Konto–Ärende, Order–Kund) | Bygger en sammanhängande "helhetsbild" över poster och processer |
| Bilagor på postnivå i kontext | Foton, signerade formulär, PDF:er per post | Bra för "filer kopplade till en post", inte för stora dokumentbibliotek |
| Händelser med hög volym (utvalda fall) | Händelseloggar via elastiska tabeller | Fungerar när du behöver lagra stora mängder händelsebaserad data i Dataverse |
Vad bör inte lagras i Dataverse
Dataverse är inte avsett att vara ett universallager för alla typer av data. En praktisk regel är att hålla Dataverse fokuserat på styrd operativ data och flytta storskaliga ostrukturerade eller analysfokuserade datamängder till plattformar som är byggda för dessa arbetsbelastningar.
Mycket stora råa datamängder – som telemetri, klickströmsdata, IoT-data eller systemloggar – passar vanligtvis dåligt i standardtabeller i Dataverse. Dessa datamängder är tilläggs-tunga och söks i stor skala, vilket hanteras bättre av analysorienterade tjänster.
Tunga dokumentbibliotek och långsiktiga filarkiv hör hemma i SharePoint. I Dataverse lagrar du affärsposten plus dokumentmetadata eller länkar. För stora mediebibliotek eller bulkbinärer är objektlagring (till exempel Azure Blob Storage) vanligtvis det mer lämpliga valet.
I fall där ett annat system måste förbli sanningskällan kan migrering av data till Dataverse leda till duplicering och synkroniseringsöverhuvuden. Istället kan virtuella tabeller användas för att exponera extern data i Dataverse utan att kopiera den – med insikten att virtuella tabeller har avvägningar och inte stödjer alla Dataverse-funktioner.
Om ditt mål är lagringsplatsen för företagsanalyser snarare än daglig operativ appdata, är ett lakehouse eller en datasjö vanligtvis en bättre grund. Ett vanligt mönster är att hålla Dataverse som det operativa sanningssystemet och sedan landa utvald data i en analysplattform för rapportering, långsiktig lagring och tvärdomänanalys.
Kärnbeslutet är om data behövs för att driva den dagliga driften eller om den primärt är för analys, arkivering eller storskalig fillagring. Att hålla Dataverse fokuserat på operativa poster skyddar prestandan och undviker oväntade kapacitetskostnader. För att göra detta beslut praktiskt fungerar tabellen nedan som en snabbguide.
| Databehov | Dataverse-lämplighet | Bättre alternativ |
|---|---|---|
| Dokumentbibliotek och samarbete | Begränsad | SharePoint |
| Massiva ostrukturerade filer/media | Svag | Azure Blob Storage |
| Telemetri, loggar, tidsserier i skala | Svag | Azure Data Explorer |
| Analysfokuserad lagring | Svag | Fabric OneLake / ADLS |
| Externt system förblir sanningskälla | Undvik ofta kopiering | Virtuella tabeller i Dataverse |
Säkerhet i Dataverse
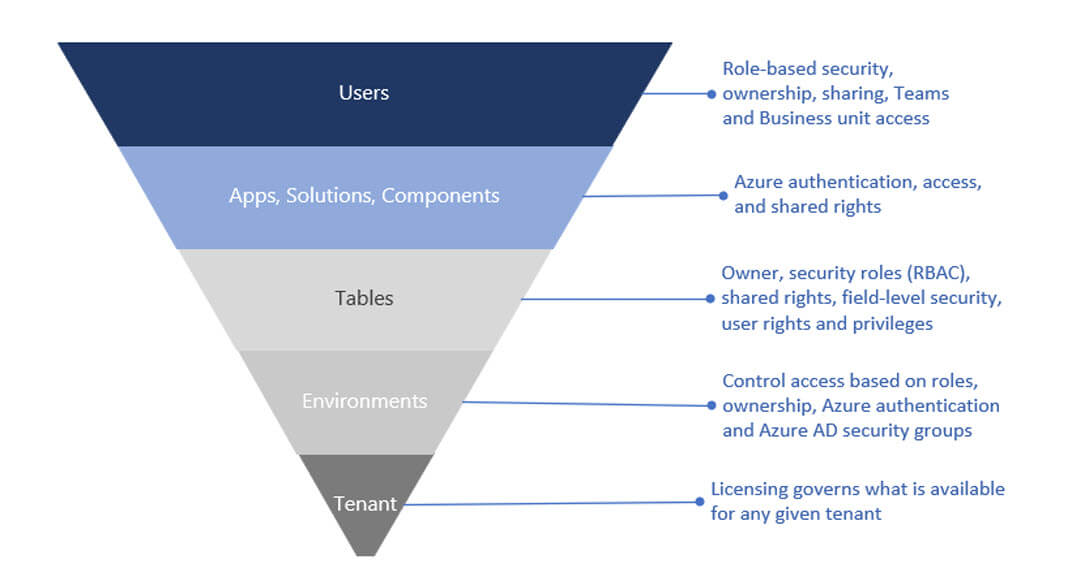
Dataverse-säkerhet är flerskiktad. Den börjar med klientidentitet och licensiering, begränsas av miljögränser och blir sedan detaljerad på datanivå genom rollbaserade behörigheter, ägarskap, delning och – när det krävs – säkerhet på kolumnnivå.
Detta är viktigt eftersom många lågkodssäkerhetsbrister inte uppstår enbart från tabellbehörigheter. De uppstår när team säkrar data men förbiser uppströmsåtkomst, appdelning eller kopplingsdrivna vägar som flyttar data utanför den avsedda gränsen.
Användare autentiserar sig via Microsoft Entra ID, och miljöer kan begränsas till specifika säkerhetsgrupper så att bara godkända, licensierade användare kan komma in. Därifrån kräver appar och flöden fortfarande styrning: identiteterna bakom anslutningar, och de rättigheter som beviljats dessa identiteter, avgör vilka externa system en app eller automatisering kan nå.
Direkt Dataverse-åtkomst jämfört med kopplingsbaserad åtkomst
Dataverse är en förstapartskälla i Power Platform. Power Apps ansluter till Dataverse med den inloggade användarens Microsoft Entra ID-identitet, och Power Automate använder vanligtvis Dataverse-kopplingen med hanterade anslutningar och anslutningsreferenser.
Den praktiska skillnaden är att Dataverse-behörigheter tillämpas av Dataverse-roller och tabellsäkerhet, medan externa system som nås via kopplingar lägger till ytterligare ett risklager kopplat till koppliningsstyrning och autentiseringsomfång.
Denna distinktion separerar två styrningsfrågor:
- Dataverse-datasäkerhet: roller, behörigheter, åtkomstnivåer och tabellsäkerhet styr vad användare kan visa, skapa, uppdatera och ta bort i Dataverse.
- Kopplingsbaserad åtkomst: anslutningsägande, autentiseringsomfång och koppliningsstyrning styr vilken data som kan röra sig till eller från externa system.
För riskstyrning över system fungerar Power Platform DLP-policyer (dataförlustrhindrande) som skyddsräcken genom att begränsa vilka kopplingar som kan användas i en miljö och vilka som kan användas tillsammans. Microsoft Purview DLP erbjuder bredare, företagsomfattande DLP-funktioner utöver Power Platform.
Rollbaserad åtkomstkontroll i Dataverse
Dataverse-auktorisering bygger på rollbaserad säkerhet. Säkerhetsroller buntar ihop behörigheter, och dessa roller kan tilldelas användare, ägarteam eller gruppteam. En kombination av åtkomstnivåer och behörigheter i en roll avgör vilka appar och data användare kan se och hur de kan interagera med dem.
Åtkomst ackumuleras över roller. Om en användare har flera roller får de den kombinerade åtkomsten från alla. Det är därför färre, väldesignade roller är säkrare än att lägga på nya roller över tid. Det är en av anledningarna till att rolldesign i Dataverse tjänar på att göras genomtänkt tidigt.
Dataverse inkluderar också fördefinierade säkerhetsroller som följer en princip om minsta möjliga behörighet, vilket ger minimal nödvändig åtkomst för vanliga användaruppgifter. Det kan vara en praktisk startpunkt för organisationer som vill ha en säker grund istället för att bygga varje roll från grunden.
Affärsenheter, team och skalbar administration
Affärsenheter är en grundläggande byggsten för säkerhetsmodellering i Dataverse. De fungerar med säkerhetsroller för att bestämma effektiv åtkomst och definierar en säkerhetsgräns i en Dataverse-databas. Varje Dataverse-databas har en enda rot-affärsenhet, och du kan skapa underordnade affärsenheter för att segmentera användare och den data de kan komma åt.
I praktiken är affärsenheter inte alltid en 1:1-avbildning av ett organisationsschema. De definieras ofta som säkerhetsgränser som gör det lättare att tillämpa konsekventa åtkomstregler i stor skala. När en användare är kopplad till en affärsenhet påverkar den kopplingen ägarskapet.
Poster som skapas av användaren ägs inom den affärsenhetens kontext, och säkerhetsroller kan ges omfång så att användaren kan komma åt poster som ägs av den affärsenheten.
Till exempel kan användare i olika affärsenheter begränsas till poster som ägs inom sin enhet, vilket hjälper till att avskärma åtkomst utifrån organisatoriska gränser.
Användare A är kopplad till Division A och tilldelad en roll med omfång för den affärsenheten, vilket ger åtkomst till poster ägda i Division A (Kontakt #1 och Kontakt #2). Användare B är kopplad till Division B och kan trots en liknande roll inte komma åt Division A:s kontakter – utan har istället åtkomst till poster ägda i Division B (Kontakt #3).
I den modellen tillhör användare en affärsenhet, och åtkomst skalas vanligtvis med säkerhetsroller, team och hierarkisäkerhet. Använd delning selektivt för undantag, inte som den primära åtkomstmodellen.
Team är det administrationsskikt som gör detta skalbart. Istället för att tilldela roller användare för användare tilldelar du säkerhetsroller till team och hanterar medlemskap via Microsoft Entra ID.
Ett Microsoft Entra-gruppteam kan ha säkerhetsroller tilldelade och äga poster, medan medlemskapet härleds från Entra-gruppmedlemskap när användare kommer åt miljön. Det här mönstret centraliserar livscykelhantering av identiteter i Entra ID och håller rolltilldelning konsekvent när personer börjar, byter grupp eller slutar.
Postägande och delning
Poståtkomst i Dataverse formas av flera samverkande faktorer inom Microsoft Dataverse säkerhetskoncept:
- Användarens säkerhetsroller och åtkomstnivåer
- Användarens affärsenhetskoppling
- Teammedlemskap (inklusive gruppteam och standardteam)
- Poster delade direkt med användaren eller ett team
Den resulterande åtkomsten förblir additiv inom miljön. Delning finns för att möjliggöra samarbete när rollbaserad och ägarskapsbaserad åtkomst inte räcker – men det bör förbli en undantagsmekanism snarare än den primära åtkomststrategin.
Omfattande delning ökar administrationsarbetet och gör åtkomstanalys svårare i stor skala. När kravet är förutsägbar chefs-synlighet snarare än ad hoc-samarbete är hierarkisäkerhet ofta ett bättre alternativ än storskalig delning.
Praktiska scenarier för riskminskning
Säkerhet blir lättare att förstå när det kopplas till verkliga situationer: ett för brett delat kalkylblad, en automatisering som flyttar data till fel plats, eller en sen förändring som ingen kan förklara. Scenarierna nedan visar hur Dataverse minskar dessa risker genom klientidentitet, miljögränser, rollbaserad åtkomst, koppliningsstyrning och granskning.
Scenario 1: Begränsa åtkomst till känslig kund- och finansiell data
Ett vanligt mönster är att fakturerings- och kunddata finns i delade kalkylblad. Ekonomiteamet exporterar en lista för att jaga förfallna fakturor, lägger till betalningsnoteringar och skickar tillbaka via e-post. Med tiden multipliceras kopiorna, den "senaste versionen" blir oklar, och åtkomsten blir för bred eftersom filen måste vara enkel att dela. Känsliga fält som bankuppgifter eller kreditgränser blir synliga för personer som inte behöver dem.
Med Dataverse kontrolleras åtkomsten innan användare ens når data: miljöer kan begränsas till godkända användare, och roller definierar vad varje jobbfunktion kan visa eller redigera. Känsliga fält kan skyddas med säkerhet på kolumnnivå, så att användare kan arbeta med samma poster utan att se begränsad data.
Affärseffekt: Färre oavsiktliga exponeringar och en tydligare efterlevnadsprofil eftersom åtkomst styrs av policy, inte av filer.
Scenario 2: Förhindra oavsiktlig eller skadlig dataläckage
Ett team bygger en canvas-app och lägger till ett par flöden för bekräftelser och rapportering. Med tiden dyker fler flöden upp i olika avdelningar. Ett flöde skickar data till en personlig lagringskoppling för enkelhetens skull. Ett annat postar kunduppgifter i en chatt. Inget av detta är illvilligt, men affärsdata lämnar nu kontrollerade system via vägar som är svåra att spåra.
Dataverse minskar den här risken genom att flytta kontrollen till plattformsnivå. Power Platform DLP-policyer kan begränsa vilka kopplingar som är tillåtna i en miljö och vilka som kan användas tillsammans. Det blockerar riskfyllda dataförflyttningar innan de blir en del av den dagliga driften. Rollbaserad åtkomstkontroll begränsar ytterligare vad en användare eller ett tjänstkonto kan extrahera.
Affärseffekt: Färre läckagevägar som standard, och styrning som skalas eftersom administratörer ställer in policyer en gång istället för att granska varje automatisering.
Scenario 3: Upptäcka och reagera på misstänkta ändringar
Ett ekonomiteam märker att fakturaposter ser inkonsekventa ut, eller att ett nyckelfält som en kreditgräns ändras oväntat. I filbaserade processer är utredningen långsam: du kontrollerar kalkylbladsversioner, söker i e-post och förlitar dig på minnet – men kan ändå inte bevisa vad som hände.
Med Dataverse-granskning aktiverat på kritiska tabeller kan teamet granska ändringshistorik för att bekräfta vad som ändrades, när och vilken identitet som gjorde uppdateringen. De kan korrelera det med klientens inloggningsloggar för samma tidsperiod. Om aktiviteten ser misstänkt ut kan administratörer snabbt inaktivera åtkomst i miljön, återkalla åtkomst i Entra ID vid behov och eskalera svaret.
Affärseffekt: Snabbare utredningar och snabbare inneslutning eftersom bevis och kontroller är inbyggda i plattformen.
Dataverse-lagring och licensiering förklarat
Vad driver lagringstillväxt?
Dataverse-lagringstillväxt drivs vanligtvis mindre av raddata och mer av operativa vanor. De vanligaste källorna till oväntad tillväxt är bilagor och granskning.
- Bilagor lagrade i Dataverse (filer och bilder kopplade till poster) kan expandera snabbt när team behandlar Dataverse som ett dokumentarkiv.
- Granskningsloggar och plattformsloggar kan växa tyst när granskning är aktiverat brett utan en plan för lagringsbegränsning.
- Händelsedata med hög volym (till exempel telemetribaserade poster) kan blåsa upp lagringen om den behålls i operativa tabeller istället för att dirigeras till analysplattformar, eller till elastiska tabellscenarier när det är lämpligt.
Affärstakten är enkel: Lagringstillväxt är förutsägbar när du fattar tydliga beslut om vad som hör hemma i Dataverse och tillämpar dem konsekvent.
Hur mäter Dataverse lagring?
Dataverse spårar lagring i tre kapacitetspooler, och varje pool beter sig på olika sätt.
- Databaskapacitet täcker strukturerad operativ data lagrad i tabeller, inklusive relationer och radvärden.
- Filkapacitet täcker bilagor kopplade till poster, som dokument, bilder, PDF:er och videor.
- Loggkapacitet täcker granskning och andra operativa loggar som genereras av Dataverse-användning.
Dessa pooler spåras på organisationsnivå (din Microsoft-klient), och förbrukning kan övervakas i miljöer. Eftersom poolerna är separata kan en organisation ha bra ställt med databaskapacitet men ändå uppleva kostnadstryck från fil- eller loggtillväxt.
Hur bidrar licensiering till kapacitet?
Licensiering bidrar till Dataverse-kapacitet via tre mekanismer: en engångsbaslinje, löpande ackumulering och tillägg när du överstiger berättigandet.
| Mekanism | Vad det innebär | När det är mest relevant |
|---|---|---|
| Standardberättigande för klient | Initial baslinjekapacitet från den första kvalificerande prenumerationen | Vid start av adoption eller övergång från kalkylblad |
| Ackumulerad kapacitet | Ytterligare kapacitet som läggs till när du köper fler licenser | Vid skalning av appar över team och avdelningar |
| Kapacitetstillägg | Köpt kapacitet för databas-, fil- eller loggpooler | När tillväxt överstiger berättigandet på grund av bilagor, granskningar eller användning med hög volym |
En separat modell kan gälla i pay-as-you-go-miljöer, där kapacitet och överskridande hanteras på miljönivå snarare än att dra från poolad klientberättigande. Se Bilaga B för teknisk not om kapacitetsackumulering och ett exempelberäkning.
Hur hanterar man kostnader och undviker överskridanden?
Behandla Dataverse-kapacitet som en hanterad affärsresurs
Kostnadskontroll i Dataverse är primärt en operativ disciplin. De mest förutsägbara organisationerna behandlar lagring som en mätbar resurs, fastställer tydliga styrningsregler för vad som hör hemma i Dataverse och granskar användning rutinmässigt istället för att reagera efter överskridanden.
Håll Dataverse fokuserat på operativa poster, inte allt
Dataverse fungerar bäst som det operativa sanningssystemet för styrda processer. Använd det för strukturerade affärsposter och arbetsflödestillstånd som kräver säkerhet, granskning och konsekvent logik över appar och automation. När team använder Dataverse som ett generellt filarkiv eller ett långsiktigt analysarkiv blir kostnaderna svårare att förutse och prestandan kan försämras.
Bilagor och granskning är den vanliga kostnadsöverraskningen
Mest oplanerad tillväxt kommer från filkapacitet och loggkapacitet. Bilagor kopplade till poster kan expandera snabbt när användare lagrar stora dokument direkt i Dataverse. Gransknings- och plattformsloggar kan också växa tyst när de aktiveras brett utan lagringsbegränsningsplan.
Ett praktiskt tillvägagångssätt är att bara lagra poster på postnivå som verkligen behöver leva med transaktionen, och att aktivera granskning medvetet med en definierad lagringspolicy.
Granska lagring månadsvis så att problem framkommer tidigt
Engångsdimensionering är sällan tillräcklig. En lätt månadsgenomgång är vanligtvis mer effektiv: kontrollera databas-, fil- och loggförbrukning per miljö, identifiera vad som växte och varför, och tilldela en ägare att åtgärda grundorsaken. Det omvandlar lagring från ett tekniskt problem till ett operativt mätvärde som ledningen kan styra.
Avlasta medvetet för att hålla kostnaderna förutsägbara
Använd etablerade avlastningsmönster istället för att låta lagringen sprida sig. Som nämnts tidigare, använd SharePoint för dokumentbibliotek och håll Dataverse fokuserat på den operativa posten plus länkarna.
För långsiktig analys och storskalig händelsedata, flytta utvald data till en analysplattform snarare än att behålla allt i det transaktionella lagret. När avlastning är avsiktlig förblir Dataverse snål och kostnadsprognoser blir mer tillförlitliga när adoptionen växer.
Är Dataverse rätt för din verksamhet?
Dataverse passar väl när problemet inte längre är "vi behöver ett nytt verktyg", utan "vi behöver ett pålitligt ställe för operativ data."
Dataverse är troligen värt det om det mesta av detta stämmer:
- Dina team förlitar sig på kalkylblad, delade filer och e-post för att spåra arbete, och den "senaste versionen" är ofta oklar.
- Du planerar att bygga interna appar eller automatisera arbetsflöden, och behöver konsekvent data och behörigheter bakom dem.
- Du är redan investerad i Microsoft 365, eller du överväger Dynamics 365 och vill ha en datamodell som kan skalas med det.
Det är dags att gå bortom kalkylblad
Kalkylblad slutar fungera när de blir system: flera ägare, ständiga exporter, dubbla kopior, godkännanden via e-post och processer som fallerar när en person är borta. Om det beskriver din verklighet är en styrd dataplattform vanligtvis nästa steg.
Om du planerar att använda AI-upplevelser i Microsofts verktyg är ren och behörighetsstyrd operativ data ett av de mest effektiva sätten att minska risk och förbättra kvaliteten på svar och automation.
Kom igång med Dataverse
Börja med en kort discovery för att definiera processen, grundtabellerna, säkerhetsmodellen och eventuella integrationer som är viktiga. Välj sedan ett fokuserat pilotanvändningsfall där framgång är lätt att observera. Involvera både affärs- och IT-intressenter tidigt så att datamodellen och åtkomstdesignen är rätt från start.
Mät framgång i affärsresultat: färre manuella handoff:ar, mindre dubbelinmatning, snabbare cykeltider och bättre synlighet i rapportering. Om piloten minskar omarbete och ger en enda sanningskälla har du en tydlig signal att skala upp.
Om du vill ha hjälp med att välja rätt pilot och utforma en utrullning som balanserar snabba vinster med styrning kan Precio Fishbone genomföra en fokuserad Dataverse-beredskapsanalys och rekommendera en praktisk startplan baserad på dina nuvarande verktyg, data och processer.
Bilagor
Bilaga A: Tekniska noteringar för implementatörer
A.1 Begränsningar för elastiska tabeller
Viktiga begränsningar för elastiska tabeller: Elastiska tabeller backas av Azure Cosmos DB och förbrukar Dataverse-kapacitet enligt Microsofts dokumentation. Vissa Dataverse-funktioner stöds inte, så validera aktuella begränsningar innan du använder elastiska tabeller för styrd operativ data.
A.2 Implementering av många-till-många-relationer
Relationsdatabaser representerar vanligtvis många-till-många-relationer med en kopplingstabell (intersectionstabell). Dataverse hanterar detta automatiskt för många-till-många-relationer genom att skapa en korsningstabell i bakgrunden.
Om du behöver extra attribut på relationen (till exempel "Roll" eller "Startdatum") modellerar du det explicit med en anpassad kopplingstab med två uppslagningar, istället för att förlita dig på den systemhanterade många-till-många-relationen. Mer information finns i Skapa översikt för många-till-många-tabellrelationer.
Bilaga B: Licensierings- och dimensioneringsreferens
B.1 Kapacitetsackumulering per licens
Dataverse-kapacitet ackumuleras baserat på Power Platform-licensiering. Värdena nedan är vanligt förekommande för planering och ges som en baslinje.
- Power Apps Premium (ackumuleras per licens): 250 MB Dataverse-databas + 2 GB Dataverse-fil
- Power Apps per app (ackumuleras per licens): 50 MB Dataverse-databas + 400 MB Dataverse-fil
Obs: Kapacitetsberättiganden kan ändras över tid. Använd den senaste Power Platform Licensing Guide som sanningskälla för din klient.
B.2 Exempelberäkning för dimensionering
Det här exemplet illustrerar hur ackumulerad kapacitet skalas med antal användare. Scenario: Ett SMB har 25 Power Apps Premium-användare som kör operativa appar dagligen.
- Ackumulerad databaskapacitet: 25 × 250 MB = 6 250 MB (ungefär 6,1 GB)
- Ackumulerad filkapacitet: 25 × 2 GB = 50 GB
Den här typen av uppskattning är användbar för tidig dimensionering, men verklig användning drivs ofta av bilagor (filkapacitet) och granskning (loggkapacitet). Övervaka lagringstillväxt per miljö och tillämpa policyer för fillagring och lagringsbegränsning för att undvika oplanerade överskridanden.
Dela gärna detta på

Jerry Johansson
Arbetar med IT och digitala tjänster och gör det komplexa begripligt — och ibland det enkla betydelsefullt. Med en bakgrund i journalistik bygger han broar mellan teknik och människor med hjälp av ord, strategi och lagom mycket PowerPoint. Drivs av nyfikenhet, tydlighet och kaffe.